
!j development
Programming Article:
Optimising streamed floating point processing with
Inline Assembler using SIMD instruction sets
by !jdev
©2003-2006 !j development division audio
This article is copyrighted. All rights reserved. Don't publish entirely
or parts without explicit permission.
Introduction
This short excerpt will give a raw overview, how to effectively optimizer time critical floating point processing when building applications with HLL (high level languages) like C, C++ or (Object) Pascal or whatever. It also shows you, how important is can be to take notice by new optimizations technologies from microprocessor manufacturers. The most commercial compilers obviously don't support maximum of possible optimizations directly, merely roughly or very rudimentary and complicated. There are some Processor Packs available, but the usage is very cumbersome and unsatisfactory. Also very often the final results.
Note: We don't know anything about the latest Microsoft C++ .NET Compilers. There may be a new options (G7) and additional SSE/2 optimization switches, but we have not tried this yet. Although, you cannot simply convert a normal designed application into a SSE/2 compliant, this article will clearly show why.
The entire theme is intended for experienced developers, so you need some know how of programming in general to understand all the core facts. You need also a basic knowledge of the Assembler (machine coding) language to understand the code examples, because we do not teach programming with Assembler here.
If you are an Assembler programmer, it may be good to know, that we have used common basic syntax as much as possible, so the code should be maximum portable. We don't use macros or vendor specific language extensions for this reason. Most of the commercial Assemblers differ in syntax but merely because they implement many additional definitions and macros. The basic language should be "understood" by all serious Assemblers without any problems or only minor modifications.
Assembler is well known (not to say: legendary), to being able to produce
the fastest code possible.
The big problem is, that most HLL programming languages slow down the
natural way of processing very often dramatically. Unnecessary code additions,
initialisations and lots of useless checkups slowing down the speed of
our programs at the important parts. The only way to speed up time critical
processes is often to use hand optimised assembly code. But this is not
well documented, allot more work and finally needs some experiences and
understanding of the microprocessor architecture.
We have decided to make some of our "know how" finally public
here, whatever, don't assume that this is the "nonplus ultra"
of optimised Assembly programming or so. Far away.
We are specialized in programming real time audio and multimedia software,
so the theme to get the fastest possible code is always a very important
one. But we code generally with HLL too, because this is much more efficient
in workflow of the real projects. Whatever, as much as possible we try
to optimise time critical code with hand coded inline Assembler, to get
things under control. Not to forget, that some things are even only possible
with Assembler coding.
We concentrate this article to single precision floating point processing, which is a top domain of real time audio processing and other high speed multimedia application development using this special streaming data format.
Ok, you may say now: today it is not longer necessary to program in pure machine language, because the HLL compilers have excellent optimising routines onboard. That's right. But do you know this for sure?
This lesson tries also to give some answers to this often discussed question.
Attached Material
The package for this article includes the 4 compiled example programs including the complete source code. The programs are 32bit console applications for windows 2000/XP. These application do nothing special, than the later described loop calculations in background and close automatically, after finished. The names are self describing. Simply start the applications on the destination systems and watch your CPU performance, so you can see some differences between the optimizations techniques described below.
Note: If you have an older processor, so maybe not all programs will run. We have not included any check routines to test, which processor you have. Also, for instance the 3DNow! program will not work on your machine, if you run it on a Pentium processor, vice versa you won't get the SSE/2 example starting, if you have an old Athlon and so on ...
The source code project is in Microsoft Visual C++ project format. We used Visual Studio Enterprise 7 to do that. It should be compatible with Professional and Standard versions of VC++ 7 and later, but for some reasons (new instruction set support) NOT on older VC++ compilers (i.e. VC++ 6 and below).
Inline Assembly
Lets start now.
Inline Assembly is an inbuilt support for writing Assembler code directly
into the code editor of your compilers IDE. You don't need anything additional
to do this. Fortunately the times are over, where you have to code on
ugly DOS interfaces with poorly designed text editors to write, compile
and link Assembly code manually like a nasty hacker.
All modern compilers support inline Assembly for a minimum of today's
programmers comfort. But you can of course use any other standard Assembler
of your choice too, to extract only the inline Assembler code.
Whatever inline Assembler has some great benefits, this is mainly, you
can access your C, C++ or Object Pascal variables and pointers directly
from inside the Assembler code block in your normal procedures. Also the
code will be automatically linked to your application. This simplifies
very much, how we will see.
It should be no problem to you to do the same with Delphi 7, C++ Builder 6 or any other new HLL compiler supporting inline Assembly, to get equal results.
You don't need to rip out all the code snippets here. The complete source code for the VC++ 7.0 project is available for download on this website and/or in the attached package.
An exemplary inline Assembler function looks like this (C/C++ code):
inline void
ProcessBuffersWithIA(void *pOut, void
*pIn1, void *pIn2, long
count)
{
// Using the FPU and EXX on common
(co)processors
__asm
{
mov eax, pOut
mov ebx, pIn1
mov ecx, count
; loop counter
mov edx, pIn2
label:
fld dword ptr [ebx]
; load mem, st0 = *in1
add ebx, sizeof_dword ; increase
pointer in1 by 4
fmul dword ptr [edx]
; st0 = st0 * *in2
add edx, sizeof_dword ; increase
pointer in2 by 4
fstp dword ptr [eax]
; store to mem at [eax] and pop st0
add eax, sizeof_dword ; increase
pointer out by 4
dec ecx
; decrease count
jnz label
; if not 0, go on looping
}
}
(*) For this, we assume, that we have at least an 80487 (co-)processor ( with FPU ) or above with 100% compatible Intel Architecture, because this code uses the extended general purpose registers exclusively ( EAX, EBX, ... ) and the instruction set of the FPU (floating point unit).
As you can see, the access to assembly is very easy from inside the code
editor. You write an Assembler code directly inside your HLL code, using
the __asm {...} directive. The compiler will automatically compile and
link this code without any modification into your application. There is
nothing additional required. Also the debugger works as usual with this
technique. But notice: The compiler will not automatically optimise code
written in this way, of course.
Even therefore we probably used it. ;-)
As we said before, we will not explain the syntax of any of the code snippets, as long there is nothing special. If you are a beginner in assembly programming, please read some introducing lecture. There are dozen of good Assembler books out there, some (older) of them are even free available online. We recommend the book "The Art Of Assembly" (free e-book) for a very first impression.
Short Explanation of the function: The code above, will simply add two source buffers filled with single precision floating point values (floats) together and store the result into an other output buffer. The buffers are 4byte (32bit) aligned, which is exactly the size of a float and those buffers are equal in size ( a multiple of 4byte ). That's really nothing special.
You would write such a function in pure C/C++ code like this one:
inline void
ProcessBuffers(float *pOut, float
*pIn1, float *pIn2, long
count)
{
while (count--)
*pOut++ = *pIn1++ * *pIn2++;
}
or an other variant using array operators:
inline void
ProcessBuffers(float *pOut, float
*pIn1, float *pIn2, long
count)
{
for (int
i = 0; i < count; i++)
pOut[i] = pIn1[i] * pIn2[i];
}
No matter, which of the both functions you use, the compiler will produce nearly the same result. The second one has the advantage, that it checks the variable count before processing (cannot be negative). Else, we assume you will not use invalid parameters and the given variables are valid pointers to single precision floating point buffers with the correct alignment anywhere inside your code declared and filled with some (random) data.
So you could call the function inside a simple console program with:
...
int main(int
argc, char* argv[])
{
ProcessBuffers(out, in1, in2, MAXITEMS);
// function 1
//ProcessBuffersWithIA((void*)out,
(void*)in1, (void*)in2, MAXITEMS); // function 2
printf("Finished!\n");
return 0;
}
(*) Where MAXITEMS is defined anywhere and specifies the count of items in the buffers.
In fact we will use in this way compiled programs in the following analysis to examine, how different the result by coding with assembly language can be. The compiled programs are part of the attached package.
The Analysis
To prove speed differences between different coding schemes, we use a larger loop of processing sp (single precision) float buffers for each of the both functions. We also do this multiple times, so we can measure more exactly. In fact we run the functions 32768 times with 32768 elements in each of the buffers. If you have a very slow processor, the execution time will be probably long but you can close the console any time to abort the process. You can also recompile the examples with other sizes, if you want. For this you have to modify the source code manually and recompile the examples.
The C++ version of the function will be referred as Function1 and the inline Assembly code as Funktion2 in the following explanations.
For monitoring the results we use the standard performance monitor of a Windows 2000 / Windows XP Professional (Task Manager) on different machines and processors. We will use AMD Athlon / Athlon XP processors and Intel Pentium4 processors, because we want to use different instruction sets and special registers on those different microprocessor models later.
Furthermore we don't describe the technical details of the processor implementations and instruction sets here, nor we will explain the microprocessor architectures. Also we will ignore all the stuff around the initialisation and feature detection of the systems. For detailed information, please read the recommended literature of your operating system and the technical documentation of the different microprocessors. You can often find useful things on the manufacturers websites.
1. Using hand coded FPU Assembly
At first, we will do a direct comparison of two different implemented functions (normal C++ and inline Assembly) and report the results visually with some screenshots. We will first run the Function1 and then recompile the program and run the Function2 for the pending tests. After running the test programs we will finally take a screenshot to illustrate the result.
Please note, that our assembly code is not special speed optimised but for demonstration purposes "clear" and descriptive designed.
Function1 is always the same and looks like this, as shown below:
inline void ProcessBuffers(float
*pOut, float *pIn1, float
*pIn2, long count)
{
for (int i = 0; i < count;
i++)
{
pOut[i] = pIn1[i] * pIn2[i];
}
}
Function2 is the same inline Assembly example as above:
inline void ProcessBuffersWithIA(void
*pOut, void *pIn1, void
*pIn2, long count)
{
// Using the FPU and EXX on common
(co)processors
__asm
{
mov eax, pOut
mov ebx, pIn1
mov ecx, count
; loop counter
mov edx, pIn2
label:
fld dword ptr [ebx] ;
load mem, st0 = *in1
add ebx, sizeof_dword ; increase
pointer in1 by 4
fmul dword ptr [edx] ; st0
= st0 * *in2
add edx, sizeof_dword ; increase
pointer in2 by 4
fstp dword ptr [eax] ; store
to mem at [eax] and pop st0
add eax, sizeof_dword ; increase
pointer out by 4
dec ecx
; decrease counter
jnz label
; if not 0, go on looping
}
}
The void* pointers in the function head have a special meaning, which will be explained later in the context.
Normally one could say: Oh my good, this second one looks huge and ugly!
And it seems to be much more code.
Yes. But look, what happens if we run the example:
NOTE: We don't use any compiler optimizations switch for the examples to be objective. When maximum compiler optimizations are applied per setting some of the compiler switches, the results may be more equal, at least with this first example here.
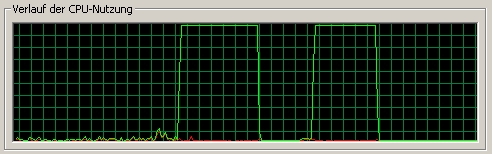
We used an old Athlon 900. First is Funktion1 (C/C++ function), second is our hand coded Assembly (Function2). On Pentium processors the result may much more clearly (our code will be faster, see below).
As we can see, the hand written machine code is faster than the C++ result,
the compiler normally produces. This is because the C/C++ compiler generates
much more machine code then you would expect by using this simple C function.
Even what "he" produces is clearly slower, if we don't use optimizations
switches. This may be different, if we apply several automatic optimizations
to the build.
Whatever, the next examples will show, that there is no such easy possibility
to switch the (for high speed designed) different new instruction sets
of modern microprocessors, like 3DNow!, SSE and/or SSE2.
Please note also: As more complex a function will be, as more problems the compiler will have to find the best possible speed optimizations. Also the compiler is very limited to automatically implement special instruction sets and optimizations techniques. The example we use is now actually really very easy to optimise by human and/or even a machine ...
But now we want go to the next level of optimising our simple code. This shows clearly, that the compiler is not always able to do this selfishly:
2. Using AMD 3DNow! Instruction set
The 3DNow! instruction set was the first high speed floating point instruction set on the market of PC microprocessors. Other than the (merely useless) first Intel MMX technology, it provides SIMD (single instruction multiple data) support for single precision floats (much more useful for audio processing, multimedia and vector graphics).
3DNow! can process 2 packed floating point values (2 x 4byte = 64bit)
at ones; this means with one single processor instruction. So we had in
fact 2 FPUs inside one AMD K6 / Athlon processor, if this were true!
Not exactly but nearly, we will see now.
One may say: But floats (4byte) have a lower precision than doubles for
instance.
That's exactly right, and therefore, they should be faster than 64bit
(in fact 80bit internal precision on the FPU) than double or extended
IEEE Standard float formats.
For audio processing and most other multimedia applications, this precision
is more than enough and offers a noticeable and significant speed increase.
The high precision, which the FPU normally produces is merely important
for astronomers, mathematicians and other scientists, but not for multimedia.
Even for those first clients, it is probably not precise enough.
Also there will be a very common heavy problem, especially with audio
processing software, using the FPU: called the "denormalization"
problem, which means, that the processor switches to denormalization mode
on very low floating point numbers to keep the highest possible precision.
This special mode uses often more than 10 times more power, so some real
time applications will collapse completely with this, unnecessarily.
But this special theme is not a part of the discussion here.
Let us see now, what the matter is with this magic 3DNow! feature:
inline void ProcessBuffersWithIA(void
*pOut, void *pIn1, void
*pIn2, long count)
{
count /= 2; // don't forget to
divide count
__asm
{
mov eax, pOut
mov ebx, pIn1
mov ecx, count
; loop counter
mov edx, pIn2
label:
movq mm0, qword ptr [ebx]
; mm0 = 2 packed floats
add ebx, sizeof_qword
; increase pointer in1 by 8
pfmul mm0, qword ptr [edx]
; nothing to say here
add edx, sizeof_qword
; increase pointer in2 by 8
movq qword ptr [eax], mm0
; store the data to memory
add eax, sizeof_qword
; increase pointer out by 8
dec ecx
; decrease counter
jnz label
femms
; clear the 3DNow! state (special case)
}
}
Note: The early 3DNow! instruction set has no division instruction for direct access available. But there are fortunately other possibilities to do it. Although, the division instruction is generally very "expensive" to the performance, so it may be a good idea to replace division instructions with some other tricks on all high speed functions too.
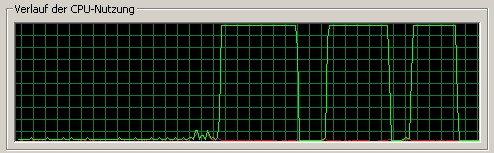
The same old Athlon 900 as above. First is Function1 (C/C++ Function), second our FPU Assembly, third the 3DNow! Assembly.
As you can see, we get indeed much better performance when running on an AMD processor with 3DNow!. The processing speed is not double as fast as our first (unoptimized) C/C++ example and only a third faster than our hand coded Assembler, because we expected double speed for Function2. Whatever, the result is better and will be more obvious on the new generation of Athlon processors (see next).
Now try this with simply setting some optimisation switches of your HLL
compiler... No, don't try it, it is not possible without creating new
data types and alignments, including additional file headers, processor
packs and other time consuming preparing. We have heard about the latest
.Net Compilers from Microsoft, but don't expect too much from those.
Although, you will never get more speed, than with coding per hand and
well designed (inline) Assembler code!
The only thing we have done, was to exchange some of the instructions of our first FPU code example and the "same" code runs finally faster on the Anthony.
Please note, that the data now must be different aligned than in our
first example ( not longer 4byte but 8byte (64bit) ) and the counter of
processing loops must be divided by 2, logically, because we process 2
floats at the same time.
Therefore we also have used the mysterious void* pointers in our inline
assembly function. So we can use one and the same function to try different
alignments, without implementing difficult intrinsic headers or type casting
for the newer "__mm64 or, __mm128" or whatever data structures.
Now we want to se, whether we can speed up the performance usage of the
CPU one times again!?
Would you say this may be impossible now? Lets see ...
1. Using Intel and AMD SSE/SSE2 Instruction set
There is a relatively new technology out there since the release of the Pentium III. After the successful AMD 3DNow! attack, Intel has released an answer to that: SSE/SSE2 implementation and their instruction sets.
Note: Newest Athlon processors also support this SSE/SSE2 feature now, but not the very first Athlon models and not 100% compatible, as we will see later.
Like before, we will exclusively look at the floating point possibilities of this new technique, whatever, there are many others too.
The SSE implementation and instruction set offers (how wonderful) 8 new 128bit registers, completely usable for single and double (SSE/2) precision floating point values. This means, we can process actually 4 floats at same time with this. This is nearly the same as we had 4 independent FPUs in our computer! But you can also use 2 double precision floats, for what ever. You can load up to 8 such packed data to the registers and use for the calculations directly inside the processor registers. So we had additional a memory access time of zero for at least 8 x 4 packed sp floating point values!
inline void ProcessBuffersWithIA(void
*pOut, void *pIn1, void
*pIn2, long count)
{
count /= 4; // don't forget to
divide count
__asm
{
mov eax, pOut
mov ebx, pIn1
mov ecx, count
; loop counter
mov edx, pIn2
label:
movaps xmm0, [ebx]
; xmm0 = 4 packed floats
add ebx, sizeof_dqword
; increase pointer in1 by 16
mulps xmm0, [edx]
; nothing to say here
add edx, sizeof_dqword
; increase pointer in2 by 16
movaps [eax], xmm0
; store the data to memory
add eax, sizeof_dqword
; increase pointer out by 16
dec ecx
; decrease
counter
jnz label
}
}
Note: Now we use 16byte == 128bit aligned data. So the counter must be divided by 4. Because we process 4 packed floating point values at the same time.
So quick and hasty, we will try this and take a look on the results... :
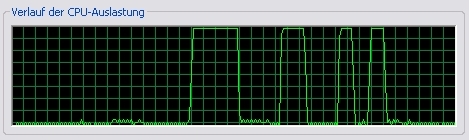
This is an Athlon XP 3000+ 2,1 GHz.
First is Funktion1 (C/C++), second our FPU Assembly, third is 3DNow! Assembly,
fourth is SSE Assembly. As you can see, the 3DNow! and the SSE seems to
have no big difference and only half as fast, not the expected quarter
?! The SSE seems to be a little bit slower than 3DNow! !? Maybe SSE will
only simulated on the latest Athlon processors (i.e. perhaps this AMD
SSE is merely a real time converted 3DNow! instruction set ) ? We don't
know ...
But the speed difference between the several Assemblies is more clear than
on the older Athlon models. Whatever, nothing tops the next example:
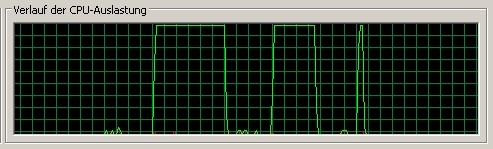
This is from Pentium4 (M) 2,0 GHz. M stands for mobile.
At first we see the Funktion1 (C/C++), second the hand coded FPU Assembly,
third the SSE/2 optimisation. The last is unbelievable. It needs less
than a quarter of our hand coded FPU Assembly. Really astonishing.
The 3DNow! program will NOT run on Pentium4, of course. But we don't need
it, because we can get much faster with SSE/2 on a Pentium4.
The Athlon seems to be faster in general with all the used examples and the 3DNow! and SSE implementations results in a noticeable speedup. Whatever, the Pentium processor is the unreached champion in SSE optimizations for floating point streams. It is definitively our recommendation.
Summary
There is a fact, that will become very obvious here. The results on several
microprocessor architectures are different. As newer the processor types
are, as more effect has individual speed optimizations. This stands somehow
in contradiction to our expectations. Whatever, normal compiler generated
code is equal slow on all tested processors. So individual speed optimizations
seems to be a MUST for today's microprocessors.
With inline Assembler we can this easy do.
Most today's software don't make (per concept) usage of the unbelievable great power of the new microprocessor architectures! An application, which uses floating point routines, especially streaming buffers, could use a quarter and less of the performance of the normal processor usage, if it was designed based on the new technologies.
But many developers fear the implementation of different instruction sets, because the overhead and this is seems to be much additional work. Indeed, it is.
Each time critical function must be implemented with at least 3 different optimizations to support all processor types: one normal (general), one for 3DNow! and one for SSE/2. And the entire design of the opcodes must be changed to fit into the special alignment requirements for each of the techniques.
The different CPU implementations are a reason too, why compilers do not apply the new optimizations per standard in its results, this would also enlarge the program sizes significantly to ensure compatibility. On the other side: Only you can prepare the special data requirements for the different optimizations techniques and only you can find the best performance structure of your code. No compiler can do this job for you, even if new switches will be available.
Fortunately the latest microprocessor families support all SSE, so the future may by much easier for developers.
Note: There are often some cases of complex algorithms, where the great possibilities of the new instruction sets are useless or at least not worth the expenditure and cannot be used.
If you look at the inline Assembly functions above, you will notice, that the differences of the diverse instruction sets are mostly minimal. Very often you can simply replace some instruction names without any additional programming. The functions above do all the same thing, only the names of the specific instructions are changed. And the data alignment, of course.
The direct usage of the inline Assembly features simplifies the usage
of the new instruction sets enormously. You should begin now to implement
time some critical code with inline Assembly. Do not blindly trust the
compiler manufacturers and also not the processor manufacturers. Best
thing to do it, is to test it yourself.
We hope, we could finally somehow convince you.
Some Disadvantages
As astonishingly and exciting this all may be, the usage of the new features instruction sets has also some little disadvantages which make it not as easy as it seems to be.
At first you have to spend much time for implementing checking routines, to examine, which of the instruction sets are supported by the destination machine. Otherwise you will force crashes and your program is completely crap, at least in the eye of the users, because he can't run it. The program will rise an exception ( "Invalid instruction!" ) and quit, if you try to use instructions not supported by the processor. The processor generates an interrupt for this.
If you want to support all modern microprocessors, you have allot more
work.
But it was not a good idea to release applications running merely on one
of the processor architectures and not on the others. If you use special
instruction sets, you have to implement all of the techniques or at least
downward compatibility. Nevertheless we have seen such developments in
the past and actually ( designed only for SSE/2...!? ). People will not
buy a new computer for your software ...
Fortunately, CPU feature detection is very easy, so this is normally not the problem. Here some examples for OS support check, CPUID examination and feature detection with C/C++:
inline int Check_OS_Support(int
feature)
{
__try
{
switch
(feature)
{
case
_CPU_FEATURE_SSE:
__asm
{
xorps xmm0, xmm0
}
break;
case
_CPU_FEATURE_SSE2:
__asm
{
__asm _emit 0x66 __asm
_emit 0x0f __asm _emit 0x57 __asm
_emit 0xc0
}
break;
case
_CPU_FEATURE_3DNOW:
__asm
{
__asm _emit 0x0f __asm
_emit 0x0f __asm _emit 0xc0 __asm
_emit 0x96
}
break;
case
_CPU_FEATURE_MMX:
__asm
{
pxor mm0, mm0
}
break;
}
}
__except (EXCEPTION_EXECUTE_HANDLER)
{
if (_exception_code()
== STATUS_ILLEGAL_INSTRUCTION)
{
return
(0);
}
return
(0);
}
return 1;
}
inline void DetectProcessor(void)
{
DWORD result = GetCPUCaps(CPU_TYPE);
if (!result)
return;
switch
(result)
{
case UNKNOWN:
strcpy(cpu_type, "Could
not identify CPU type");
break;
case AMD_Am486:
strcpy(cpu_type, "AMD
486 detected");
break;
case AMD_K5:
strcpy(cpu_type, "AMD
K5 detected");
break;
case AMD_K6:
strcpy(cpu_type, "AMD
K6/1 detected");
break;
case AMD_K6_2:
strcpy(cpu_type, "AMD
K6/2 detected");
break;
case AMD_K6_3:
strcpy(cpu_type, "AMD
K6/3 detected");
break;
case AMD_ATHLON:
strcpy(cpu_type, "AMD
ATHLON detected");
break;
case INTEL_486DX:
strcpy(cpu_type, "INTEL
486DX detected");
break;
case INTEL_486SX:
strcpy(cpu_type, "INTEL
486SX detected");
break;
case INTEL_486DX2:
strcpy(cpu_type, "INTEL
486DX2 detected");
break;
case INTEL_486SL:
strcpy(cpu_type, "INTEL
486SL detected");
break;
case INTEL_486SX2:
strcpy(cpu_type, "INTEL
486SX2 detected");
break;
case INTEL_486DX2E:
strcpy(cpu_type, "INTEL
486DX2E detected");
break;
case INTEL_486DX4:
strcpy(cpu_type, "INTEL
486DX4 detected");
break;
case INTEL_Pentium:
strcpy(cpu_type, "INTEL
Pentium detected");
break;
case INTEL_Pentium_MMX:
strcpy(cpu_type, "INTEL
Pentium MMX detected");
break;
case INTEL_Pentium_Pro:
strcpy(cpu_type, "INTEL
Pentium Pro detected");
break;
case INTEL_Pentium_II:
strcpy(cpu_type, "INTEL
Pentium II detected");
break;
case INTEL_Celeron:
strcpy(cpu_type, "INTEL
Celeron detected");
break;
case INTEL_Pentium_III:
strcpy(cpu_type, "INTEL
Pentium III detected");
break;
// ...to be continued
default:
strcpy(cpu_type, "Unknown
CPU type");
break;
}
strcpy(cpu_opt, "No extended speed optimization usable");
if
(GetCPUCaps(HAS_MMX))
{
if (_os_support(_CPU_FEATURE_MMX))
strcpy(cpu_opt, "Only MMX speed
optimization possible");
}
if (GetCPUCaps(HAS_3DNOW))
{
if
(_os_support(_CPU_FEATURE_3DNOW))
{
__3DNOW_Possible
= true;
__3DNOW_State
= true;
strcpy(cpu_opt,
"Using 3DNow! speed optimization");
}
}
if (GetCPUCaps(HAS_SSE))
{
if
(_os_support(_CPU_FEATURE_SSE))
{
__SSE_Possible = true;
__SSE_State = true;
__3DNOW_State = false;
strcpy(cpu_opt, "Using SIMD(SSE) speed optimization");
}
}
}
Other problems weight more heavily.
A second reason is, you have to take special attention to the data alignment
and building of your float buffers in general. If you don't use buffers
at all, (at least of 2 or 4 packed floats) this kind of performance optimizations
my be completely useless for you. Whatever, even if you work with streaming
buffer schemes ( larger, continuous steaming buffers works best with SIMD
), you often have to implement additional logic to your code you probably
wouldn't implement, if you were not using those optimizations.
Also you must watch very exactly the alignment of the entire data and
memory structures your program uses. The compiler often cannot do this
automatically.
Other problems can occur too.
Here an example: We have designed some audio processing plugins for VST
(virtual studio technology invented by Steinberg) in the past. This is
an open standard and excellent implemented on the original host Cubase
VST.
But there are some other host applications out there, where the creators don't implement the standard right or go their own strange way. They seriously think, they have done it better, but far away, they act like script kiddies in our opinion. There is at least one or two of those applications, which drives things crazy...
By the way, VST plugins are designed to be shareable and should work
under all compliable host applications. Whatever, the reality is different,
unfortunately. We have seen high quality professional audio plugins running
on host applications, where the latter completely disturbed the quality
and possible speed of audio processing. We will not call any of the names
here...
If you have such an host application, which gives you all the time misaligned
data for the streaming buffers and perhaps continuous changing buffer
sizes..., so it is very difficult to implement several optimizations with
SIMD technique. Also giving you single sample ticks to process complex
audio output is more than stupid ...
Because we need continuous and properly aligned data to process 2 or
4 packed floats inside the FMMX/XMMX registers at same time and at least
a reasonable buffer length. So we want buffers, as large and as short as
possible at same time. Buffer processing is the fastest with real time
audio processing, definitively.
Single value processing in contradiction, with almost skipping around
and misaligned data, is the slowest, you can imagine. Unfortunately also
many audio plugins act this way...
This weights much more on real time applications such like audio plugins, because they cannot endless collect buffers without noticeable latency, but they "should" get out a maximum of performance on today's PCs, and therefore use at least short continuous buffers with 32byte == 128bit aligned float memory. 1024 or at least 512 samples large constant streaming buffers is a good amount, a real time audio engine should provide. So we can fully use the big advantages of SSE/2, with 32byte/128bit data alignment on optimal sized buffers, which is the fastest way possible.
But some developers have understood really noting. Fucked situation...
Whatever, most professional music application creators take notice by this fact and handle streaming data buffers right, by giving you correctly aligned buffers in a SIMD compatible form - thanks god.
Extensions
We want to extend this article in the near future ( if we find enough
time to do this ).
The plan is to show, how to program real processing opcodes for filters
and effects with inline Assembly. Even 4 pole state variable filters can
be implemented very fine and speedy with Assembler.
There are undiscovered possibilities for code optimizations in audio processing with Assembler language. On thing you will get with guarantee by this. The absolute control over your code ...
...you will see.